背景
写这篇文章的原因是目前在看《Python源码剖析》[1],但是这本书的作者陈儒老师剖析源码的目的好像不是太明确, 所以看上去是为了剖析源码而剖析源码,导致的结果是这本书里面的分析思路不太清楚(可能是我的理解问题), 而且验证想法的方式是把变量值打印出来,当然这是种很好的方式,但使用调试工具显然更好一点。我读这本书和看源码的目的很简单: 为了理解计算机的运行,理解大型软件工程的设计。正如文章的题目为hack python而不是源码阅读,hack是一个理性的分析过程, 而阅读很多时候随心所欲的成分多一些。但总体的过程还是按照书中的顺序来的,这本书很明确的一点就是要做什么不要做什么, 这一点我很喜欢。可能会是一个系列,也可能只有这一篇,并不算挖坑。我更希望从多种视角来审视Python作为一门动态语言的各种特性。 作为一个还没有学过编译原理的人来说这个目标显然很难完成,但正是难完成的东西,才有完成的意义。这篇文章的源码均来自Python-2.5.6[2], 所有分析也都是基于此,编译环境是由Koding[3]提供的,还会用到gdb[4]作为调试工具。
数据结构
先来看一下PyIntObject的声明[5]:
typedef struct { PyObject_HEAD long ob_ival; } PyIntObject;
可以看到PyIntObject被声明为一个结构体,包括了*Python对象元信息* 和一个C语言的long型整数。 而Python的Python对象元信息是什么呢?这个问题牵扯到C语言中的宏[6]和Python类型系统的本质[f], 先按下不表。 封装了C语言long型整数的PyIntObject作为数据结构并没有什么能让人心潮澎湃的地方, 它的迷人之处在于算法[7],也就是PyIntObject的动态组织方式,可是我不可能仅从PyIntObject上管窥到它的组织方式, 需要更多的信息来达成这个目的。再来看源码:
#define BLOCK_SIZE 1000 /* 1K less typical malloc overhead */ #define BHEAD_SIZE 8 /* Enough for a 64-bit pointer */ #define N_INTOBJECTS ((BLOCK_SIZE - BHEAD_SIZE) / sizeof(PyIntObject)) struct _intblock { struct _intblock *next; PyIntObject objects[N_INTOBJECTS]; }; typedef struct _intblock PyIntBlock; static PyIntBlock *block_list = NULL; static PyIntObject *free_list = NULL;
这段代码对于PyIntObject的组织方式已经说得很清楚了,不用解释。下图形象一点:
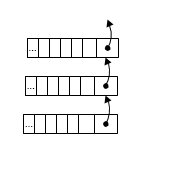
正如前面所说的,这个链表式的数据结构还是实在太简单,没多少值得把玩的地方。假设我是Python的作者, 我会想首先想这门语言出现的原因,一定是不爽于现有的某些方案,所以才要自己创造新的方案, Python被创造为一种动态类型语言,相比于C之类的静态语言优势在于“动态”二字。 但动态不是简单的声明和组织几个数据结构就完事,需要被贯穿到这门语言运行的始终。
运行时状态
下面来看一下运行时状态,根据函数名可以肯定的是fill_free_list这个函数必然会在很早的时候被调用(来准备需要的内存), 我们先不关注它到底是怎么做内存分配的,先下个断点,看一下谁第一个调用它,看到第一个触发断点的地方是_PyInt_Init, 也就是Python整型对象(类型对象)的初始化函数,推测应该是Python中的每一个类型对象都会有一个初始化函数, 在Python开始运行时完成初始化工作。来看这个_PyInt_Init函数具体包含了什么内容:
int _PyInt_Init(void) { PyIntObject *v; int ival; #if NSMALLNEGINTS + NSMALLPOSINTS > 0 for (ival = -NSMALLNEGINTS; ival < NSMALLPOSINTS; ival++) { if (!free_list && (free_list = fill_free_list()) == NULL) return 0; /* PyObject_New is inlined */ v = free_list; free_list = (PyIntObject *)v->ob_type; PyObject_INIT(v, &PyInt_Type); v->ob_ival = ival; small_ints[ival + NSMALLNEGINTS] = v; } #endif return 1; }
首先,正常情况下(排除内存不够),free* 类似命名的函数的返回值不会是NULL,所以直接忽略掉for循环中的if, 在其下设一个断点观察free_list此时的值(被赋值之前或直接观察v的值),因为这是全局变量被赋值,记录一下它之前的值, 说不定以后有用。

再往下看,除了PyObject_INIT函数(我们先不管它,等HACK Python类型系统[f]的时候再研究), 还有small_ints这个奇葩数组,根据名字,这是个在Python整型对象中必然会用到的东西,所以逃不掉了, 不过还好,不就是个数组嘛!
过程:_PyInt_Init
可以看到的是small_ints完全是一个静态的结构,它是在_PyInt_Init被调用也就是系统初始化时就被直接分配了_intblock块, 当然按照_intblock块的大小, N_INTOBJECTS为*((BLOCK_SIZE - BHEAD_SIZE) / sizeof(PyIntObject)), 这是多少呢?还需要知道sizeof(PyIntObject) ,用gdb看看到这样:

所以一个_intblock可以容纳41个PyIntObject,比small_ints的size还小(所以下面的图有问题, 不过这个信息不怎么重要,因为可以改small_ints的相关宏的值,让图变得正确)。反正在_PyInt_Init中, 只要空间不够(free_list == NULL,if条件&&左值),就调用fill_free_list分配_intblock。按照默认的参数, 大概得分配7个_intblock来完成_PyInt_Init(同样,因为要依靠参数,不重要)。
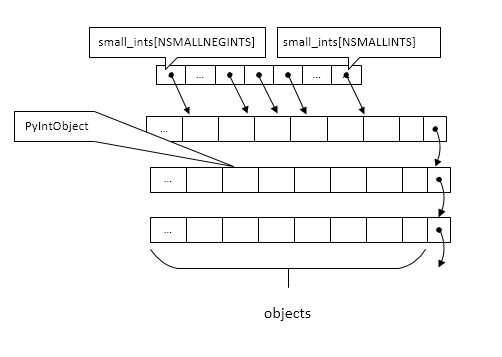
那现在,初始化过程已经完成了,我们总结一下,_PyInt_Init的主要作用就是构建一个small_ints及其空间 (在《Python源码剖析》用小整数池来描述,我觉得这么多概念容易confuse,所以直接把本质说一下就好), 但里面并没有足够的信息来判断small_ints及其空间是如何被利用的,问题(为什么需要small_ints?)依然没有被解决。 _PyInt_Init这条线索虽然断了,但好在还有PyInt_FromLong。
过程:PyInt_FromLong
注意到Python在这个时候已经经历了各种复杂的初始化过程,打印出了它的版本信息,万事俱备,只欠输入。 不关注输入过程或者调用信息,假设现在就调用了PyInt_FromLong。
PyObject * PyInt_FromLong(long ival) { register PyIntObject *v; #if NSMALLNEGINTS + NSMALLPOSINTS > 0 if (-NSMALLNEGINTS <= ival && ival < NSMALLPOSINTS) { v = small_ints[ival + NSMALLNEGINTS]; Py_INCREF(v); #ifdef COUNT_ALLOCS if (ival >= 0) quick_int_allocs++; else quick_neg_int_allocs++; #endif return (PyObject *) v; } #endif if (free_list == NULL) { if ((free_list = fill_free_list()) == NULL) return NULL; } /* Inline PyObject_New */ v = free_list; free_list = (PyIntObject *)v->ob_type; PyObject_INIT(v, &PyInt_Type); v->ob_ival = ival; return (PyObject *) v; }
构造一个Python整数对象需要一个long型整数,如果这个long型整数大小是在-NSMALLNEGINTS到NSMALLPOSINTS之间, 就认为它是一个小整数,在small_ints空间中找到封装该小整数的PyIntObject并调用Py_INCREF方法。 这里通过命名可以知道Py_INCREF方法的作用是对对象的引用数做自增操作,具体实现不深入。 当然上面只是针对小整数的情况,大整数是怎样处理的呢?继续往下看就可以知道。过程跟_PyInt_Init中一样, 一样的通过判断条件语句的右值来调用fill_free_list方法。
其实大整数对象和小整数对象的区别就在于: 1. 小整数对象是在系统初始化的时候就为其分配了内存空间PyIntBlock(也就是 _intblock),并写入值, 而对于大整数如果现有的之前分配好的PyIntBlock中有空间没用完的话就直接把值写入该块 (当然写之前还要移动free_list并对对象做初始化操作),如果用完了就调用fill_free_list新建PyIntBlock。 2. 当要用一个小整数来构造小整数对象时,只对其相应的引用计数器做自增操作, 而不像大整数那样做复杂的函数调用和内存分配操作,目的当然是时间效率,典型的那空间换时间的做法。 3. 本质上二者在内存中没有任何区别,小整数和大整数的界限可以当作参数来自己配置也可以说明这一点, 不过这个界限究竟设为多少Python的效率能达到做好的平衡呢?不知道默认的参数设置成那样的原因是什么,有没有更加科学的参数?
后记
作为第一篇关于Hack Python的文章,里面有很多东西都比较啰嗦。要做的是还原整个探索的过程,包括所有走过的弯路, 尤其要关注的是为什么,而不仅仅着眼于是什么。
对于Python类型系统的探索需要明确以下几点:
1. 概念:对于概念基本原则是越少定义越好,因为很多东西本质上都是一回事,但是一些基本的约定还是很重要的, 可以避免每次都重复啰嗦。在类型系统部分中定义如下:类型表示PyXXXObject对象,如PyIntObject;对象表示例化后的类型; 类型初始化函数表示在Python初始化时调用的用来初始化类型的函数,如PyInt_Init;构造函数表示构造对象需要的函数, 如PyInt_FromLong。
2. 研究范围:在以后的hack对象系统中,默认只研究关于本类型的内容,对于整个类型系统的宏观概览不涉及;除非用于比较, 其他类型不涉及;与C语言相关的基本概念不涉及,只给出资料;与研究工具相关的步骤不涉及,只给出结果和基本参考资料。 主要目的在于着眼于每种类型,在研究完所有类型后再总结整个类型系统。
3. 对于类型系统的研究由本文可以得出以下顺序: 类型基本的数据结构-基本类型数据结构的组织-类型特殊过程分析和解读-细节-总结。
文章里面包含链接有碍于流畅阅读,所以取消文章内的链接,在末尾加参考资料部分以示引用或概念解释。
资料:
- [1]《python源码剖析》
- [2]Python-2.5.6
- [3]Koding
- [4]GDB
- [5]声明
- [6]宏
- [7]Python的类型系统总结
延伸:
- 使用gdb调试运行时的程序小技巧